A paradigm shift in scientific discovery
A few weeks before Jim Gray lost in his solo sail trip to Farallon Island near San Francisco in January 2007, this great American computer scientist and the 1998 Turing award winner had envisioned a paradigm shift in the practise of science as a result of the increasing volume of data generated by scientific experiments and instruments, in which he coined it as “the fourth paradigm”[1]. More than a decade later, we witnessed how data-intensive methods have been adopted to harness the vast amount of information and knowledge hiding behind the deluge of data. From the petabyte of readings collected by the detector in the Large Hadron Collider deployed in CERN, to the millions of texts created by social media per second, various tools and technologies have been made and adopted by the scientific communities to collect and process them—for particle physicists to answer a frontier question related to the force of the universe in the former, and the latter for the social scientists to perform a sentiment analysis for a behavioural study.
With the wider use of sensor and Internet of Things (IoT) technologies, the fourth Industrial Revolution (IR4.0) has brought in another wave of data tsunami. Traditional social economies activities are now becoming more knowledge intensive and innovation driven, as identified in the 10-10 Malaysian Science, Technology, Innovation and Economic (MySTIE) Framework. For instance, we see the adoption of UAV technology together with advanced intelligence systems in modern rice production. Images taken by the drone are streamed back to the Cloud via 4G network, to be processed with the machine-learning model for a real-time analysis on the crops’ health. This enables the necessary intervention to be taken to increase the yields later. We see the importance of data been used across all social-economy sectors and we know the key to the success is heavily relying on whether we have the right tools and the know-how to facilitate the data exploration process.
Datascope – a new instrument for exploring data
Four hundred years ago, mankind invented telescope to explore the celestial objects in the limitless universe. With the current deluge of data, we need a “datascope” to accelerate the data analysis process in exploring and exploiting the wealth of data. The datascope should provide the necessary functionalities in each of the phases in the data lifecycle: acquisition, processing, analysis, curation, sharing and reuse. The data acquired from various sources needs to be organised in the data storage platform before it can be further processed. The processing of large volume requires a high-performance computing platform, especially when the machine-learning (ML) methods are used. A typical ML model training process requires the use of graphical processing unit (GPU) and the computational power that is beyond a normal laptop can provide.
Once the data has been analysed and results been obtained, it is now entering the post-research phases. To extend the longevity and ensure the reusability of the data, we need to curate the data—adding useful metadata to describe it. The curated data is then deposited into organisational or community-driven repositories, for a long-term data preservation and storing. The data repositories are integrated with the national or domain data discovery services, such as the Malaysia Open Science Platform[2], to increase the visibilities and sharing of the data. Data can then be used to fuelled future research, and this completes the entire data lifecycle.
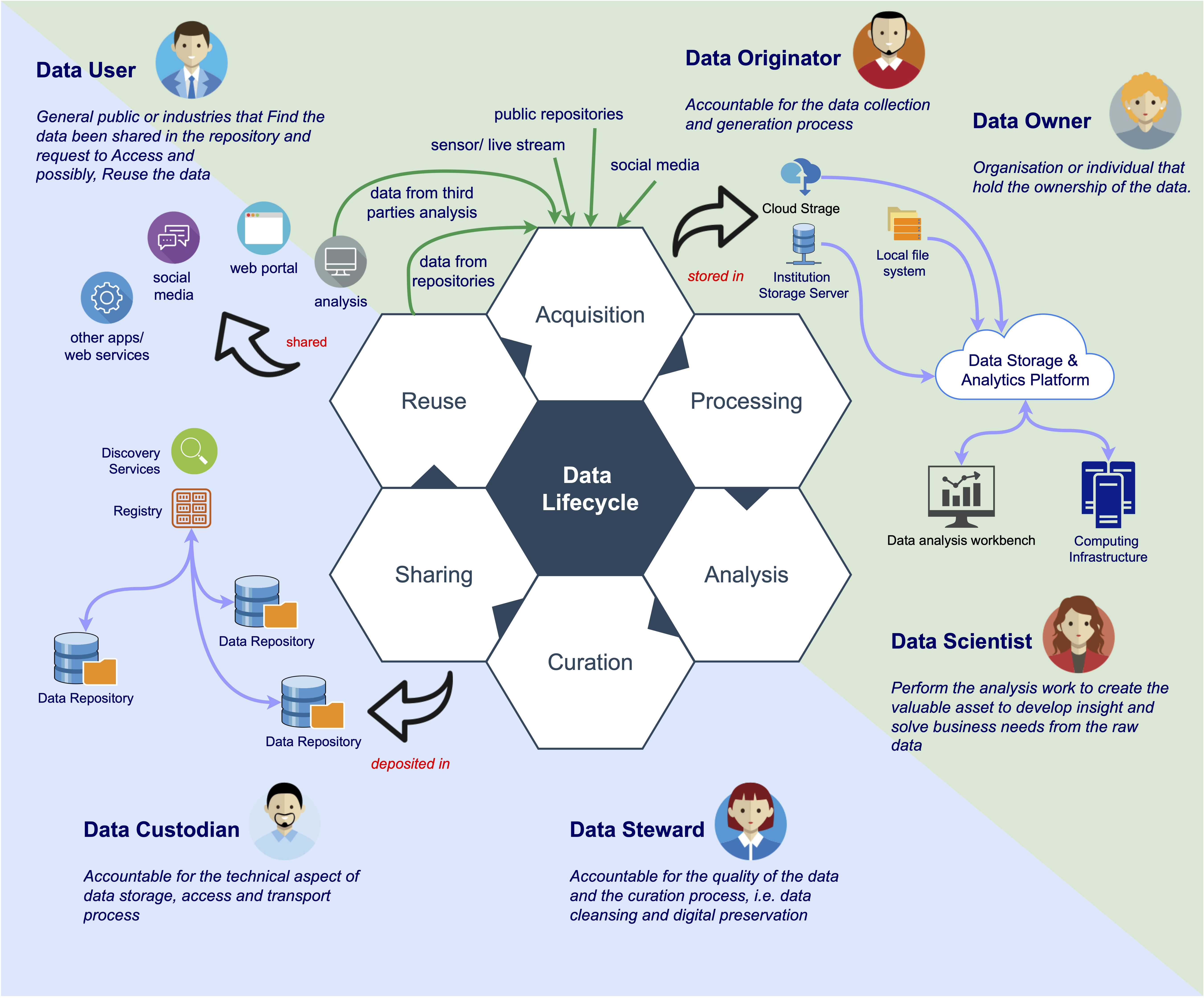
Seeing the importance of supporting the data-driven research in UM, Prof Noorsaadah Abd Rahman, the former Deputy Vice-Chancellor (Research & Innovations), had formed the Data-Intensive Computing Centre (DICC), also known as UM HPC unit, in December 2015. DICC[3] has been given two important tasks: to conduct data-intensive research and to provide High Performance Computing (HPC) service to the campus communities. Currently, DICC is operating a HPC cluster consists of 11 AMD Opteron nodes (a total of 704 CPUs and 2.8TB RAM) and 4 AMD EPYC nodes (a total of 384 CPUs and 1TB RAM), and a small GPU farm comprises Nvidia Tesla K10, K40, V100S and Titan GPU. These computing resources are connected via 10Gbps network to two distributed storage systems: a permanent storage running on Ceph (87TB) and a high-performance parallel file system running on Lustre (230TB). A 400TB storage system has been set up to perform the daily backup of the production system. The entire system is connecting via a 1Gbps MyREN network to the rest of the world.
Data-intensive research odyssey
To do advanced science, we need the advanced tools. A simple analogy will be the Formula One racing. To win the race, you need the top-notch technologies, a competence team and nevertheless, a good driver. Since UM embarking on High Impact Research a decade ago, we have recruited many world-class “F1 drivers”. The question is, are we supporting them well, to allow them to soar?
Technical Expertise – the supporting team
Many research projects are facing a common problem—lacking expertise in the IT strategy planning and implementation. Data-intensive research usually involves advanced computing aspect that beyond a domain researcher can comprehend. Thus, an ideal project team should include IT expert since day one. A real-world example was an astrophysics project that approached DICC a year ago. The project aims to set up an international observatory platform, by streaming live data from radio satellite dish from several locations, into a central station abroad. The success of project depends heavily on the network bandwidth connecting to the central station and the data storage service. Unfortunately, the researchers only approached DICC when the project comes to implementation stage, where it is too late to make anything corrective measure.
Funding – the technology
“People only interested to fund rocket science, but not the rocket launcher”, said an attendee of the 2019 Beijing CODATA high-level workshop on Implementing Open Research Data Policy and Practice. This is a non-trivial problem faced by world-wide advanced-computing service providers, and unfortunately, it happened in Malaysia too. Our ministries only fund high-impact research, or those with commercialisation-ready output. We do not have a national advanced-computing facility, or the grant to establish one, that can provide the essential support to data-intensive research. It is like giving our elite driver a commodity car and hoping that they can still win the match. “We carefully formulate our problem to ensure the computation can be completed using the modest DICC resources, otherwise our students cannot graduate”, told by a computational physicist during a user engagement workshop we had two years ago.
Researchers’ Competency – the driver
The last challenge is related to the researchers themselves. You need to be well-trained and skilful to manoeuvre the F1 racing car in the circuit, and so does advanced-computing facilities. To adopt data-intensive methods in the research, we need to spend time in learning the necessary IT skillset to formulate your solution, and equally important, to use the machines. Many researchers have the wrong impression that using the HPC cluster is nothing different than using their personal computer. This answers why most of the tickets raised in the DICC service desk are mainly related to users’ own capabilities and understanding.
Building ramps for the researchers
“Intellectual Ramp proved invaluable in accelerating the passage across the ‘chasm’ and facilitate the broad adoption of data that enables researchers to move incrementally from their current practice into the adoption of new methods”, said by Malcolm Atkinson, the former UK e-Science Envoy, back in 2010. “Ramps grow in different parts of the ecosystem. Resource providers may provide documentation, software and training to facilitate use.”
DICC mission is to enable scientific discoveries through the exploitation of advanced computing technologies, by providing research communities with excellent IT service and support in addressing research computing challenges. Our principle is to make advanced computing easier for the researchers through the setting up and operating these necessary ramps. Our researchers can follow a detailed online documentation to run their experiments in the HPC cluster, without the needs to worry about the complexity of the system itself. We are also conducting users training sessions for new users, and all of the materials, including the recording of the previous trainings are made available on our website[4]. Users can reach us easily through a service desk[5], to report for any problems with the service, or to request for new services.
Recently, DICC added a new tool to our HPC services, which is the Open OnDemand[6] portal, developed by the Ohio Supercomputer Center, the University of Buffalo Center for Computational Research, and the Virginia Tech. This portal allow our users to submit and manage their computational experiments in a user-friendly way. Through a common web browser, users not only can browse, upload and download their files stored in the HPC storage system, but also sending a new calculation into the HPC cluster and monitor its progress. For beginner, the OOD portal provides a seamless and painless way to access to advanced computing infrastructure, without going through a steep learning curve. As for the experienced users, they can monitor their computation, and perform necessary tuning to get the most out of our computing resources.
On the other hand, UM has launched the UM Open Science (UMOS) initiative to facilitate the research data management process. The UMOS is currently led by Prof. Shaliza Ibrahim, the Deputy Vice-Chancellor (Research & Innovations), and a steering committee involving the library, the research management centre, and the UM Centre of Information Technology. The UMOS is focusing on the 4Ps under three pillars: Policy & Process, People, and Platform.
UM Open Science (UMOS)
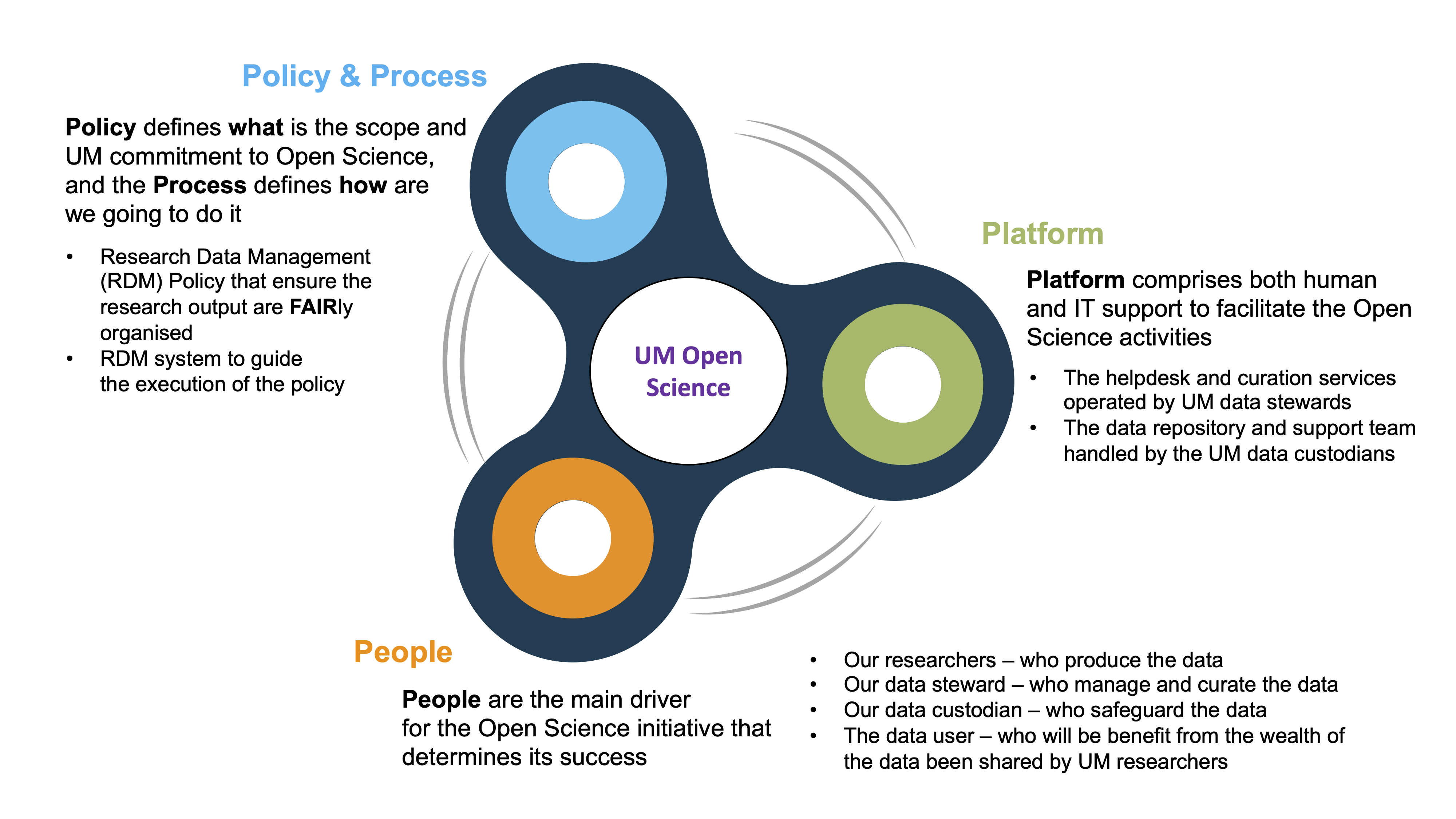
The first pillar is to establish the research data management (RDM) policy that set the scope of UMOS, with the relevant processes in managing research data. UM RDM policy adopts the globally recognised FAIR principle, which ensure all the research data produced by UM communities is Findable by public, Accessible via our UM research data repository, Interoperable with national and international platform, and Reusable, under well controlled condition. One of the important processes is the research data management plan (DMP). DMP describes the data that will be acquired or generated, and how it will be managed during the entire project duration, as well as the long-term data preservation plan, as mentioned earlier in the research data lifecycle.
The second pillar focuses on the capacity building activities to prep UM communities in moving the UMOS agenda. It comprises stakeholder engagements to increase the awareness among our researchers, who are the data originators, and a series of training programs created by MOSP, that targets at upskilling our librarians to become data stewards that managing the research data and assisting the researchers in the RDM processes. Data stewards are the main driving force for open science, to ensure the research data are FAIRly complied. The third pillar aims to establish the platform to facilitate the open science activities. It consists of a computer platform for researchers to managed and deposit their data, which is operated by DICC and UM Centre of Information Technology; and a human platform operated by the data stewards to provide a helpdesk and data curation services to the researchers.
Surfing the data wave
We are now in the era of data-driven world. The massive scale of data been used and been generated in the IR4.0 research is inevitable. It requires us to rethink the way we deal with data, making it a first-class citizen in our research. We need to craft a data-intensive research strategy and the subsequence implementation plans, to put UM in the position to lead the nation, and to impact the world.
The wave is coming. Whether grabbing a surfboard or a buoy is entirely up to you to decide. I am ready to surf. How about you?
[1] The Fourth Paradigm: Data-Intensive Scientific Discovery: https://www.microsoft.com/en-us/research/publication/fourth-paradigm-data-intensive-scientific-discovery/
[2] Malaysia Open Science Platform (MOSP): https://www.akademisains.gov.my/mosp/
[3] Data-Intensive Computing Centre: https://www.dicc.um.edu.my/
[4] DICC HPC Document: https://confluence.dicc.um.edu.my/
[5] DICC Service Desk: https://jira.dicc.um.edu.my/servicedesk/
[6] Open OnDemand (OOD): https://openondemand.org/